以下是近期使用JMP进行条件筛选的实际例子。由于我之前并未使用过这种方法,其中存在许多探索的因素。
这是一个固相反应,使用TEMPO+, Br-, TEMPO三种试剂。前期实验表明,TEMPO+是当量反应物,Br-是一种催化剂,TEMPO对反应的影响未知。三者投料量对反应的影响似乎非常复杂,至少产率与投料量的关系不是单调的,而且三种试剂投料量与产率的关系似乎存在很强的相互作用。现需要优化三者的当量,以下的当量用方括号表示。
首先确定三个变量的取值范围。当量属于连续变量,在初步尝试中,选定TEMPO和TEMPO+都最大加到2 eq,Br-最大加到4 eq。根据已知信息,显然当TEMPO+用量过小时没有尝试的必要;但另一方面,由于不知道TEMPO有没有作用、作用有多大,不排除TEMPO和TEMPO+在化学计量上可以共同起作用的可能,故需验证TEMPO+小于1 eq但存在TEMPO时的反应表现。因此,决定加上一个限制条件:虽然TEMPO和TEMPO+都可以小于1,但[TEMPO+] + [TEMPO] > = 1必须成立。由于已知[Br-]对反应至关重要,确定[Br-]应处于[0.1, 4]的区间。
使用JMP软件进行实验设计。点击实验设计->定制设计,填写变量和约束信息。在“模型”里,选择交互作用->二次,如此建立后,程序将尝试拟合如下形式的响应函数:
yield = 斜率 + c1 * [TEMPO+] + c2 * [Cl-] + c3 * [TEMPO] + c12 * [TEMPO] * [Cl-] + c23 * [TEMPO+] * [TEMPO]
其中包含斜率项、3个因子的一次项(主作用)、2种交叉项(交叉作用)。
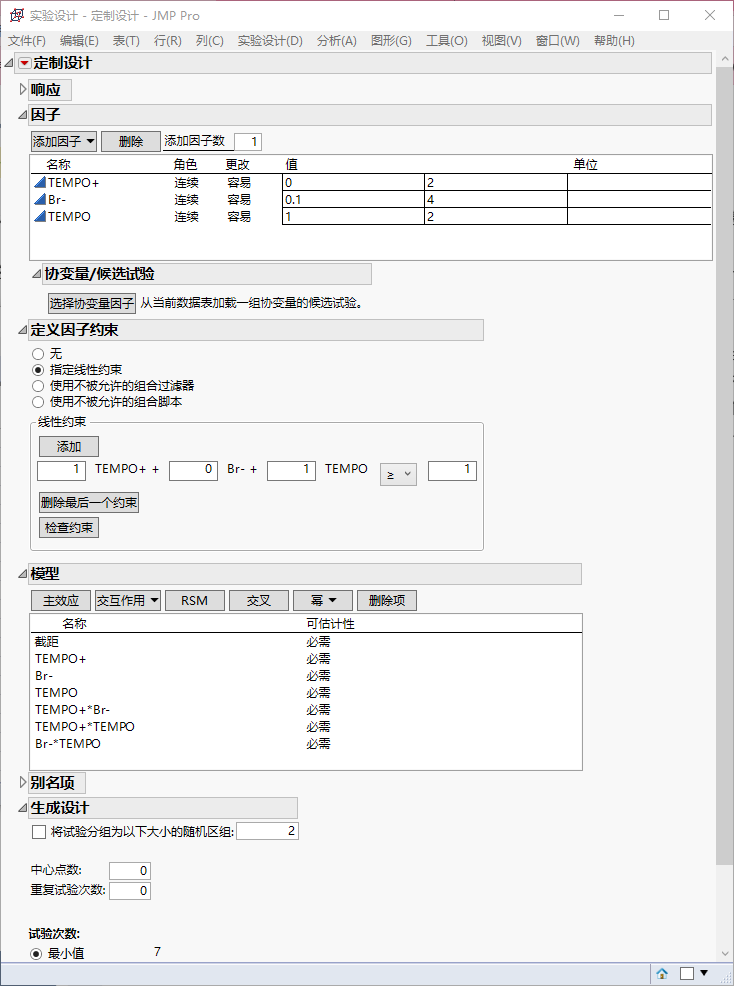
在试验次数中,系统推荐12个点。出于成本考虑,这里选择最少的7个点先试试。点击“制作设计”,系统会遍历各种可能的设计方案,从中选出最具代表性(在各变量的各方向上都能带来均衡且最小的方差的设计方案)。点击“制表”,就得到了实验表格:
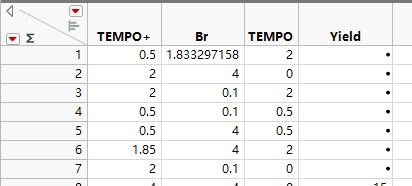
这样设计出来的试验方案和人们naively进行的“控制变量法”很不一样。它比较侧重于各变量在区间端点处的取值,各变量共同变化。用人眼分析这种实验的结果通常是比较困难的,需要用程序进行后处理。
把数据填进去,果然很不规则:
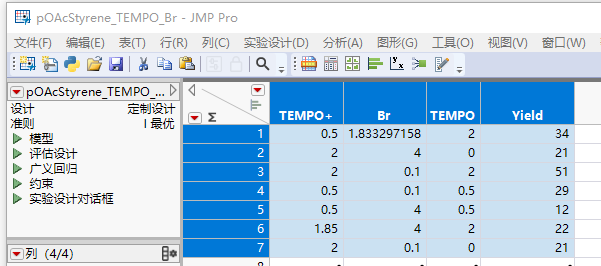
点击界面左侧“模型”处的绿色三角形,弹出后处理对话框,进一步确认设置:
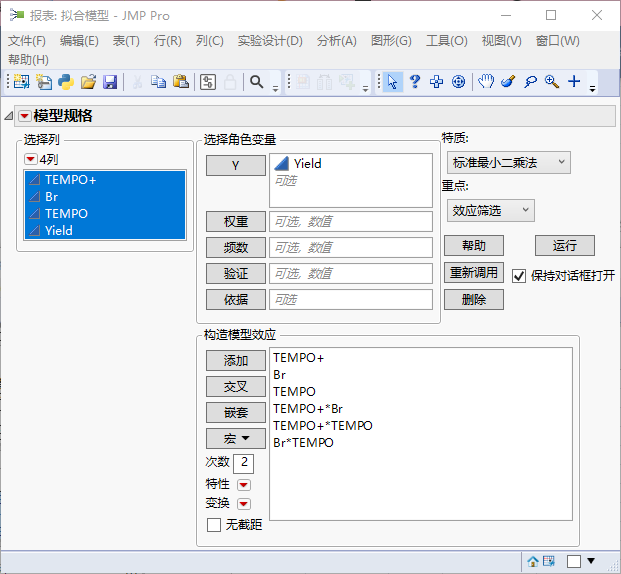
点击“运行”,会弹出模型对话框:
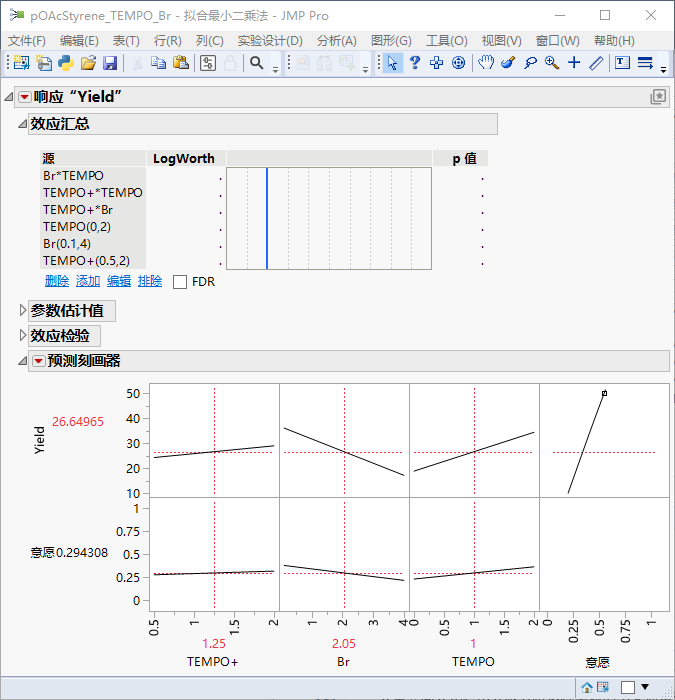
对话框下方的“预测刻画器”里显示了产率随各变量的变化趋势。“意愿”相当于是一个奖励函数,横坐标是产率。由于我们希望产率最大化,意愿随着产率增加是线性增加的。在Yield一行、左边三个因子的曲线框里,拖动红色十字,可以观察各因子处于某些数值时的预测产率。例如上图中,三个因子分别为1.25, 2.05, 1时,预测产率是26%.
但现在的结果不能使用,因为我们进行的实验太少,刚刚达到拟合所需6个参数的最小值数量,没有更多数据用于检验模型。恰好,在前期实验中我们还有4组数据,把它们填进去,就可以得到各因子的p值 、模型的残差、预测的不确定度范围等信息,这对于确定模型是否有效至关重要。
注意:先进行最小数量的实验,再填写些其他实验的结果不是一个好做法!一方面,这种后加的数据没有经过科学的选取,不能代表在参数空间里有足够的代表性;另一方面,由于这些实验不是同一批进行的,还可能受更多误差的影响。如果要采用并非同一批生成的数据,严格的做法是对试验进行分组处理。
使用这拼凑出来的共计11组数据,再次进行主效应+交叉项的拟合,并且勾选“无截距”,因为很显然当什么试剂都不加时产率为0。这次可以进行模型检验了:
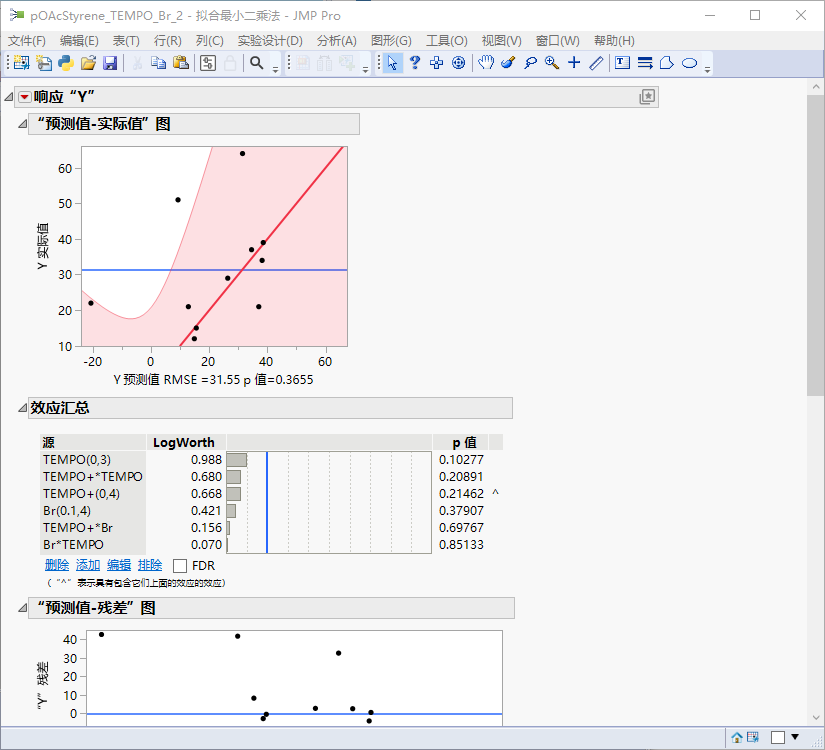
可见,对于这个体系,主效应+交叉项的模型相当差!
在“效应汇总”中,可以看到各因子的p值。p值最大的几个可以视为对产率的影响比较微弱。当然我们希望模型尽可能简单,可以排除掉p值最大的几个因子。但不论如何,这个模型对反应体系的表现都太糟糕了。这也和前期试验带来的印象相符:这个模型有很强的非线性效应。为此,需要使用二阶模型。
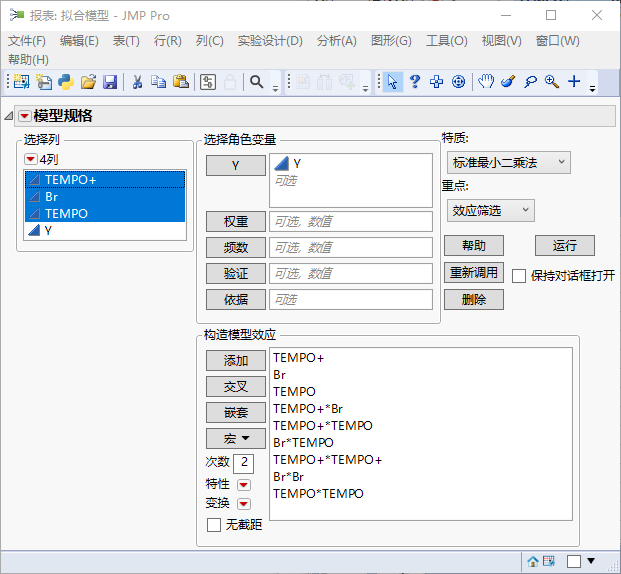
在主效应+相互作用的模型中,产率随各因子的偏导都是常数,因此它无法描述那些产率随着某些因子的变化存在极大或极小点的情况。在拟合模型对话框中,选择3个自变量因子,点击“构造模型效应-宏-响应曲面”,由于“次数”处为2,程序会自动添加3个二阶项。同时勾选“无截距”,这次拟合效果相对较好:
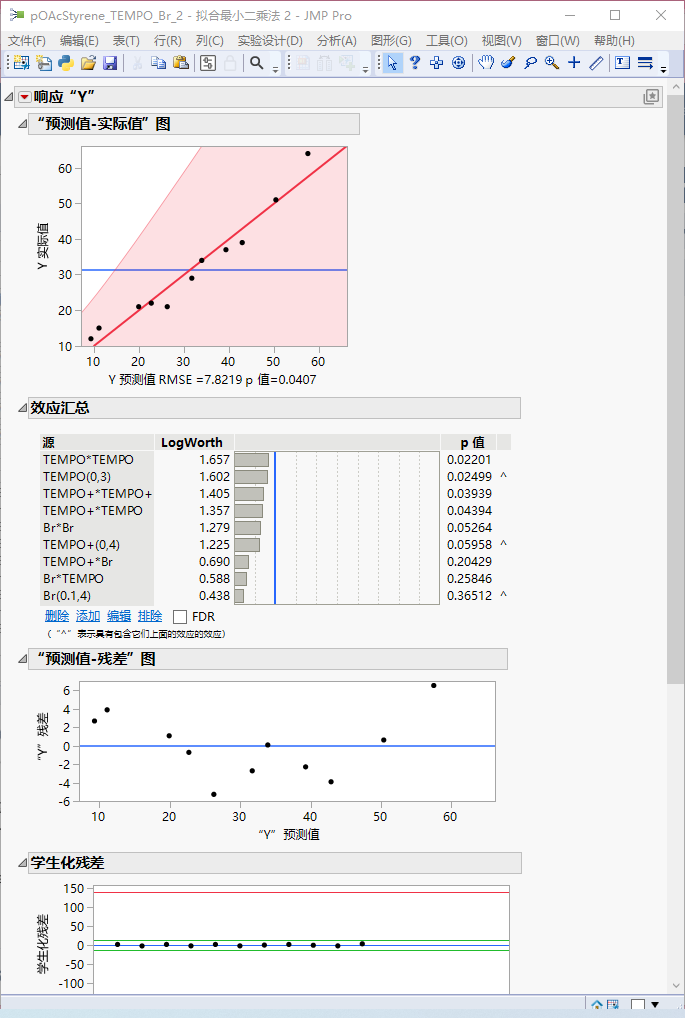
拟合效果变好是必然的,因此现在我们有9个变量了,却只有11组数据。不论如何,我们先分析一下它带给我们什么启示。
首先,[Br-]的p值是所有因子中最大的,反而[Br-]*[Br-]的p值只有0.053.看来这个体系比较奇怪,对一次项(主效应)不敏感,反而对二次项非常敏感。观察下面的刻画器:
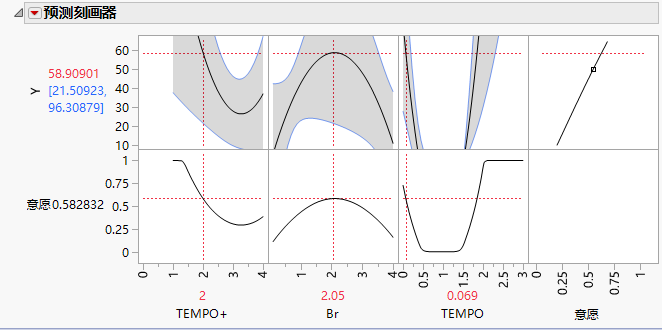
现在的模型的定量精度仍然十分有限,因为对于部分情况模型给出了负产率(如TEMPO当量在1左右时)。尽管不太尽如人意,我们还是最大程度利用模型带来的信息。例如,[Br-]存在一个最优取值(2 eq左右),而且这个最优取值对TEMPO、TEMPO+的数值不敏感(拖动另两个因子上的十字,观察产率随Br-变化的曲线,极大值点位置几乎不动)。因此,[Br-]取2 eq似乎是比较合适的,至少应该是某个中间数值。[TEMPO+]和[TEMPO]则都存在极小值,因此它们应该要么尽可能小,要么尽可能大。最终,我们选定了几组根据这个模型预测比较好的条件(12 - 14),实际实验后补充了上去:
遗憾的是,这几组实验的产率并不令人满意,还没有之前几组中的最大者(实验11)高。但这无妨,利用补充的数据,重新拟合模型,仍然限定截距为0,并排除了p值最大(>0.8)的两个参数。由于之前补的实验中[TEMPO+]最大取到了4 eq,将它的取值范围重新设置成了[0,4]。
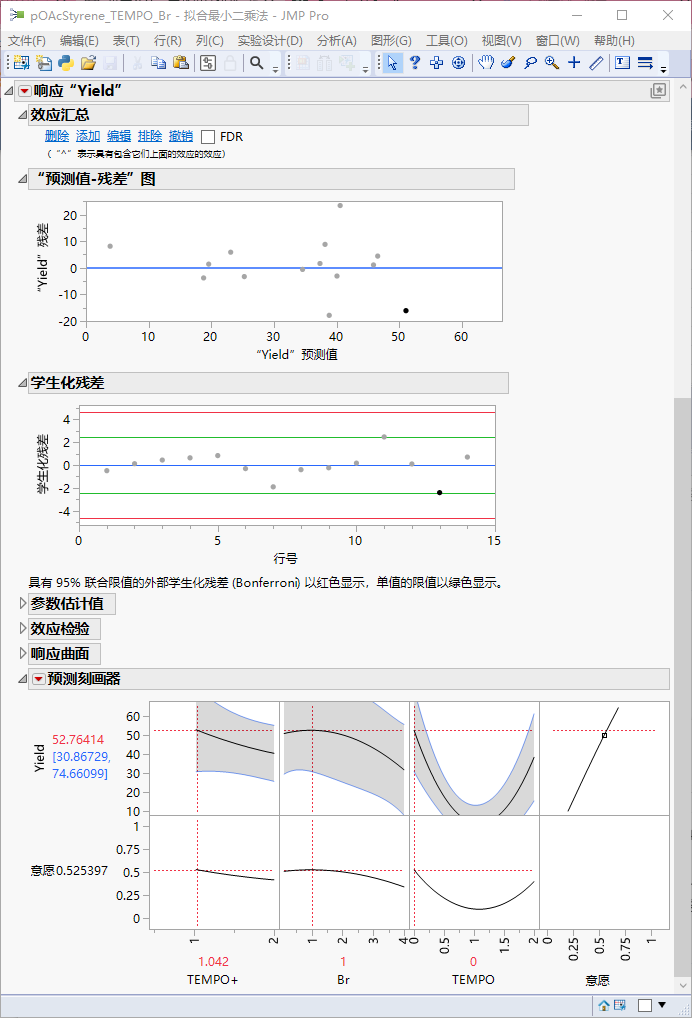
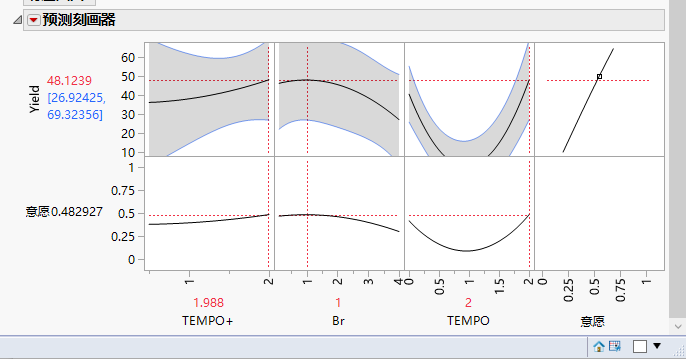
这次,模型给出了不同的预言。[Br-]曲线中依旧存在一个极大值,只不过这次模型给出的最优取值是1 eq。[TEMPO]曲线有极小值,因此它要么不加,要么多加;[TEMPO+]曲线不再出现极小值了,当TEMPO当量小时,产率随[TEMPO+]增加而降低;但当TEMPO当量大时,产率则随着[TEMPO+]增加而升高,而且曲线的右端比左端更高。
这个模型的检验表现还不错,产率误差在10%左右。不过,根据目前的试验,[0,2]以内的取值都被比较充分地探索过了。因此,接下来试试固定[Br-]为1 eq,选取[TEMPO]=2或3 eq的情况,由于此时[TEMPO+]似乎取大当量有利,将它的取值也选为2 - 3 eq.实验结果如下:

这几组的产率在所有数据点中都属于是不错的。虽然并非全都拔尖,但第15组77%的产率已经可以接受了。由于进一步优化可能要扩展到更多当量,花费很多个当量的试剂而提高10%量级的产率并不合算,因此条件优化到此为止,选择[TEMPO+] = 2 eq, [Br-] = 1 eq,[TEMPO] = 3 eq作为最终条件。
这个条件优化过程虽然一波三折,但最终也有了比较好的结果。其中很多波折应该说都是跟不断补充数据的添油战术有关的,这导致了实验的代表性严重下降。如果一开始就按照二阶模型设计实验,并且按照程序推荐的实验数量,而不是过于吝啬地使用最小数量的实验,应该能更加顺利地得到良好的结果。另一方面,尽管看起来曲折,但考虑到这个反应产率随当量的响应相当复杂(实际做过几遍前期探索后就会感受到它的复杂性,通过人工筛选是相当困难的),也体现出了实验设计方法的优越性。