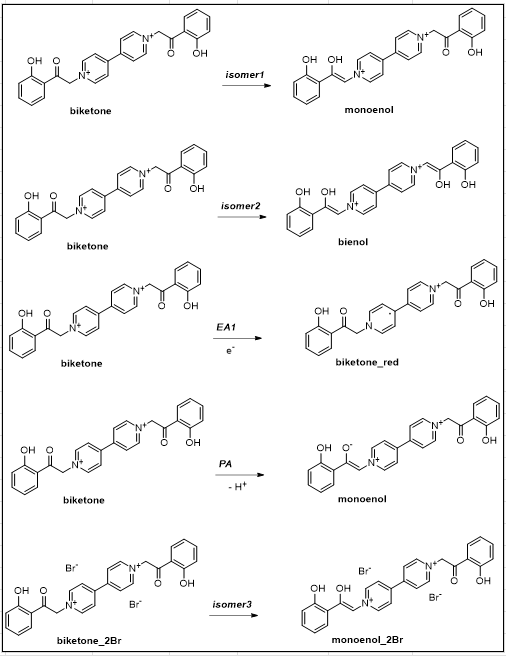
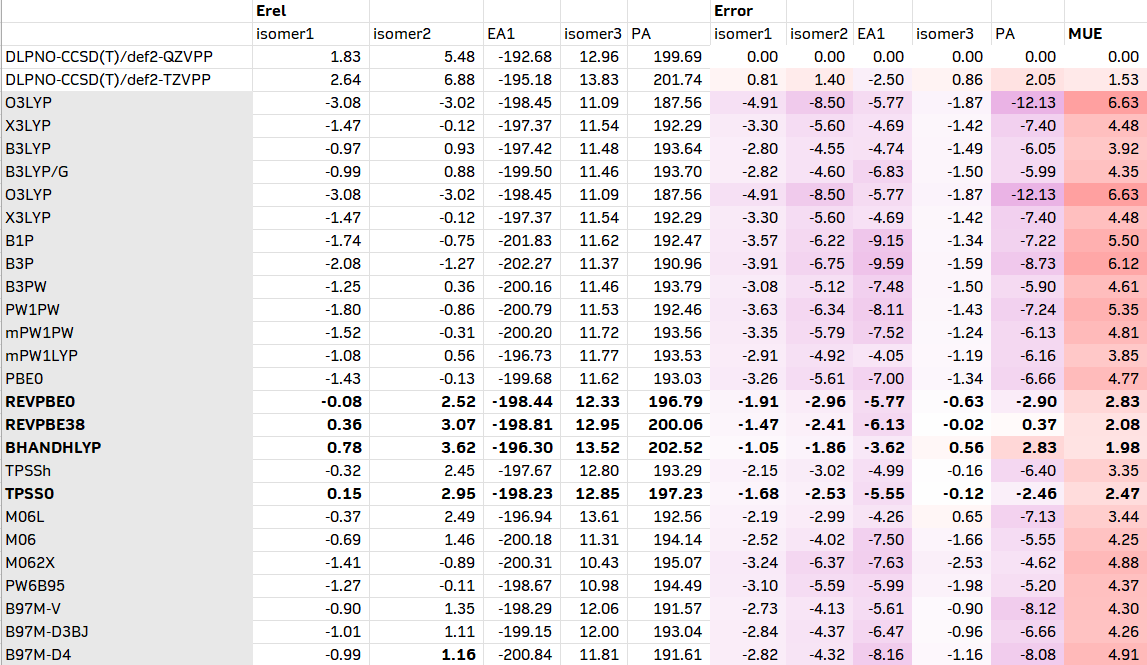
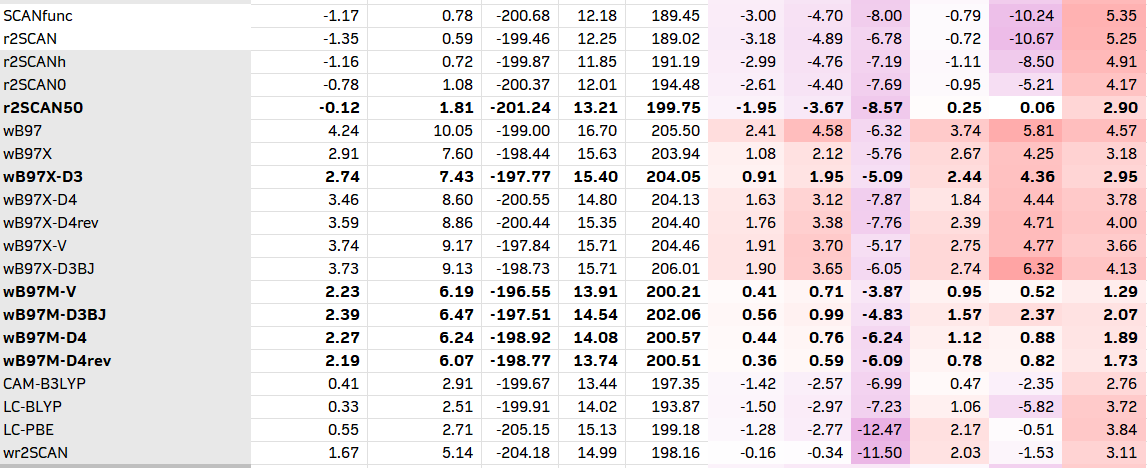
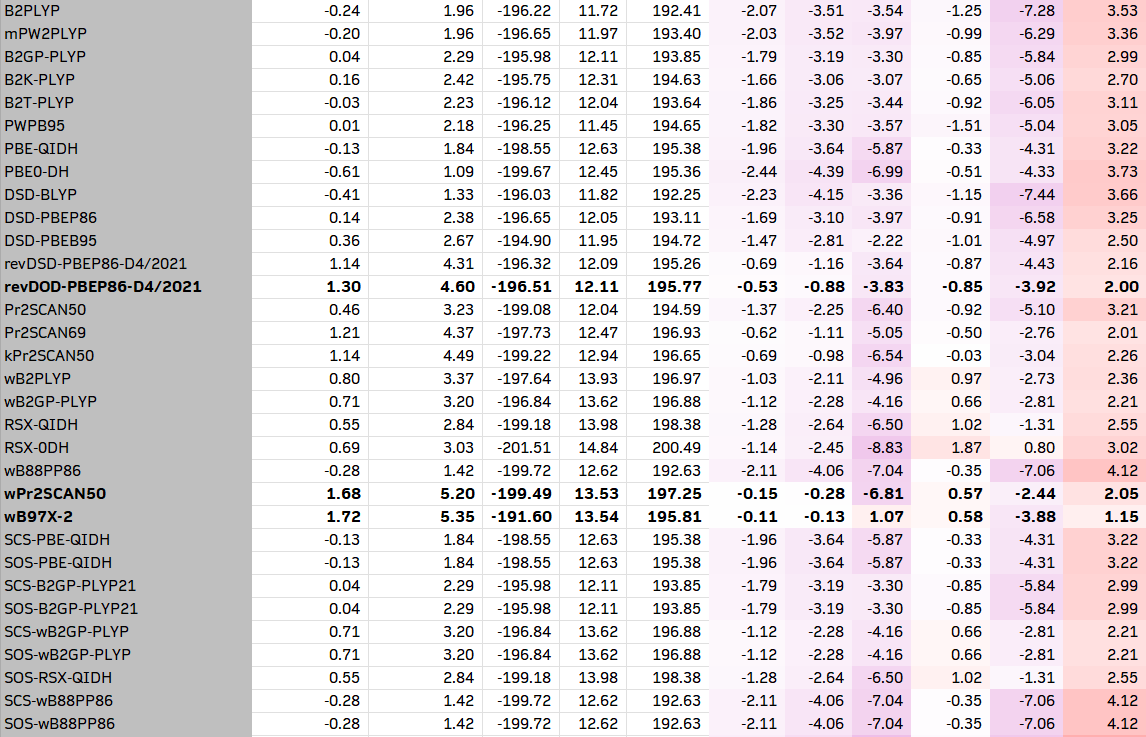
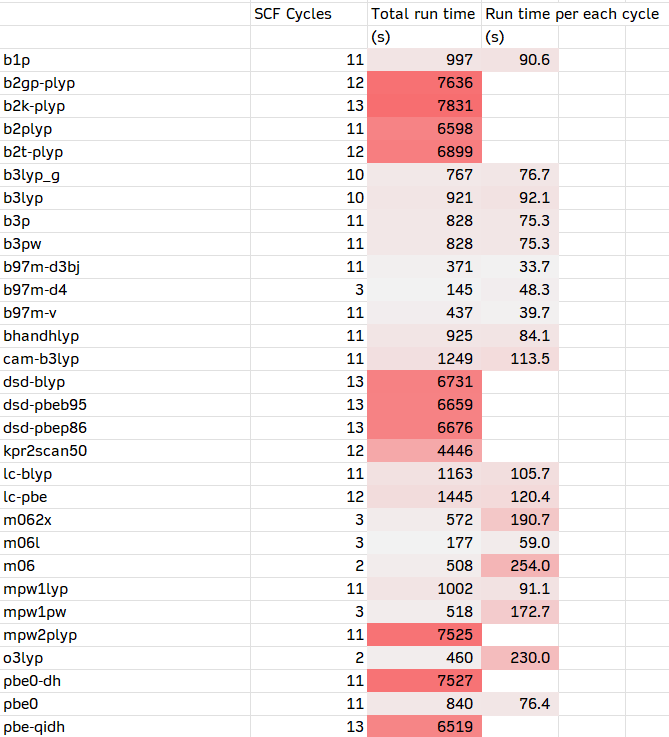
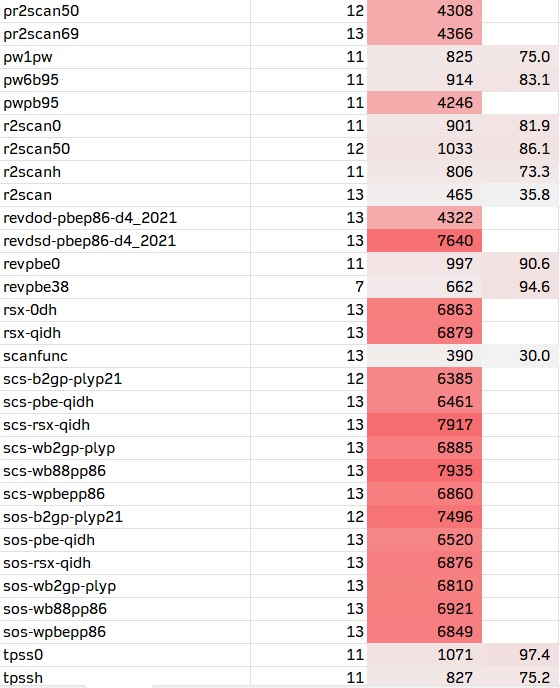
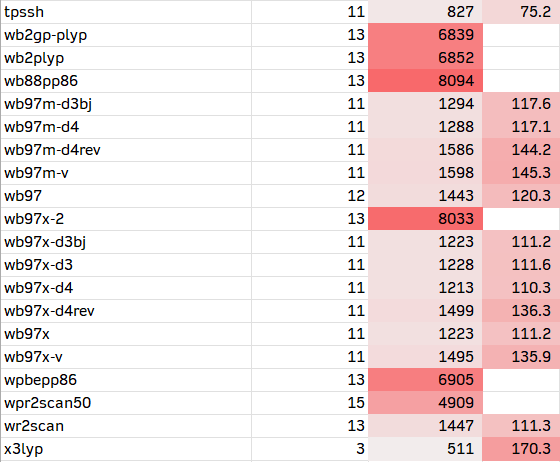
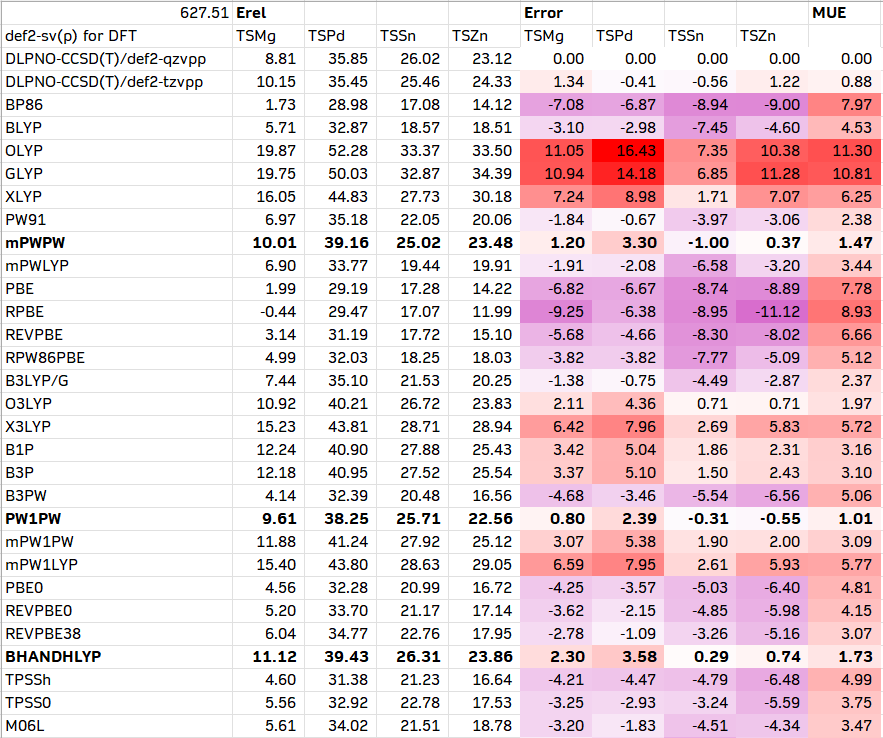
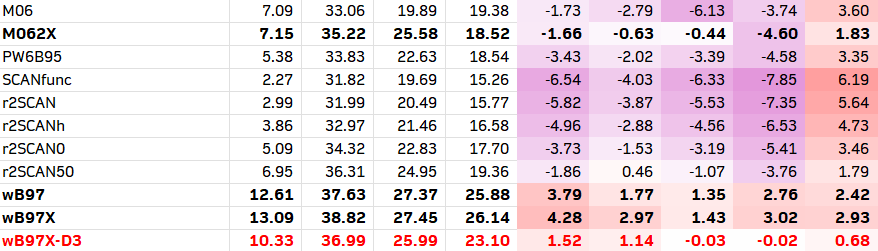
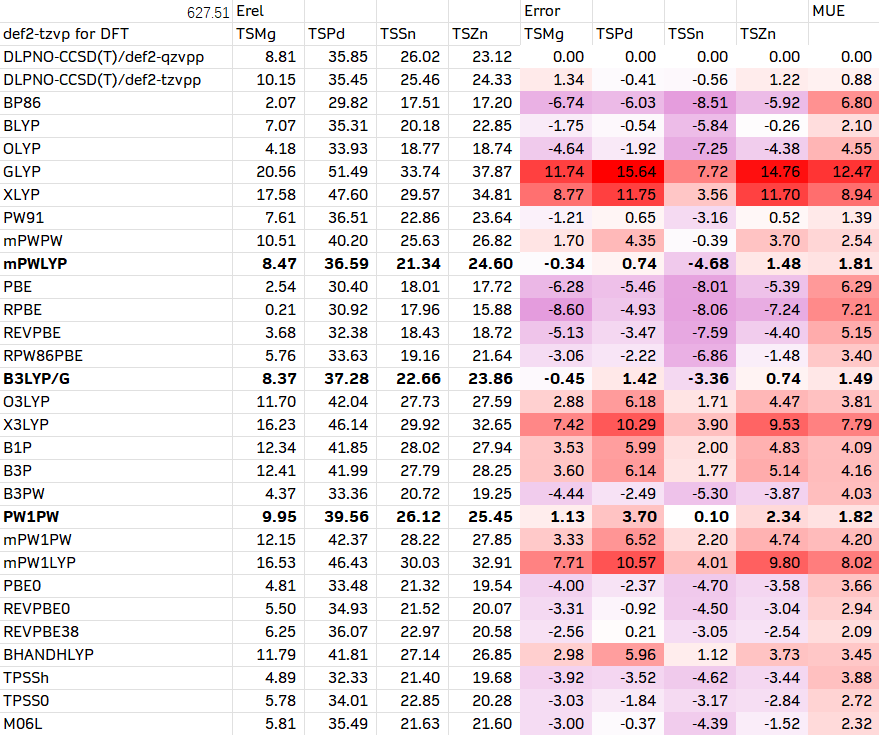
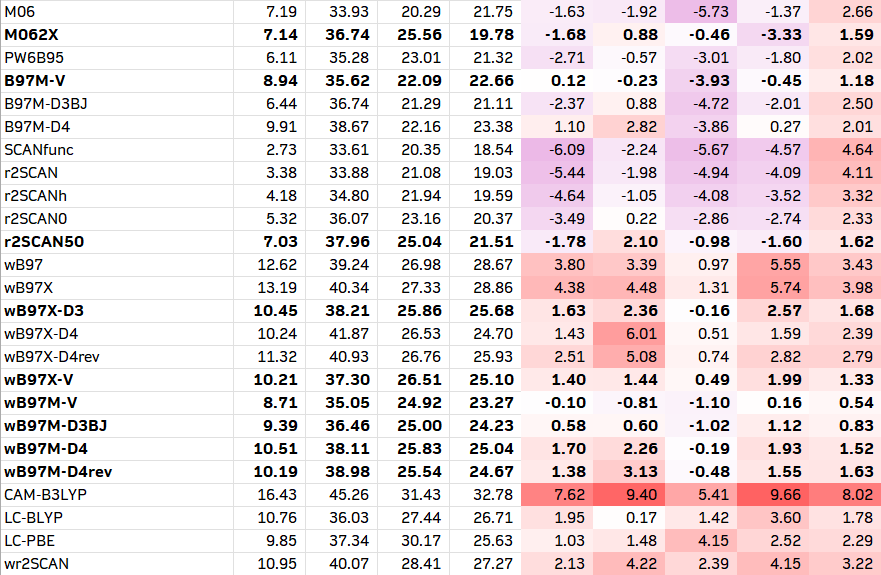
1. 通用的测试方法
由于ORCA对新泛函的支持很好,建议使用ORCA进行泛函测评,非常方便。由于手动建立输入文件比较繁琐,这里给出一个有用的测评脚本,可以自动化生成输出文件。
这个脚本由GPT5生成。感谢现代AI,让编程效率提高一个数量级。根据我的prompt,大家也很容易知道这个脚本怎么使用:
请为我写一个用于生成ORCA泛函测试输入文件的bash脚本。要求:
它接受2个参数:template_name和functional_list。template_name是一个.inp文件名,而functional_list是一个纯文本文件,每一行是一个泛函名字。假如template_name叫做xxx.inp,则针对functional_list的每一行(假如是aaa),将在jobs目录(如果没有则新建一个)下生成一个名为xxx_aaa.inp的文件,将xxx.inp中的{name}替换为aaa。如果aaa中间有空格,则生成的文件名取第一部分。例如,假如这一行是b3lyp d3bj,则生成的文件名为jobs/xxx_b3lyp.inp,内容中{name}被替换为b3lyp d3bj。
为了方便你理解,以下是一个.inp文件示例,叫做bienol.inp:
%pal nprocs 28 end
%maxcore 2000
! def2-qzvp def2-qzvp/c rijcosx {name}
*xyz 2 1
C -2.93920800 0.88058700 -0.01165500
C -1.56885300 1.02250400 -0.00899400
C -0.73161900 -0.06663600 -0.28324100
C -1.35851800 -1.29151500 -0.56149500
C -2.72824200 -1.38826700 -0.55820600
H -3.60499500 1.71178800 0.19933100
*
以下提供一个functional_list文件的内容示例:
B3LYP/G D3BJ
O3LYP
X3LYP
在这个例子中,最后需要生成jobs/bienol_b3lyp.inp,jobs/bienol_o3lyp.inp,jobs/bienol_x3lyp.inp三个文件。
以下是这样得到的自动化测试脚本:
#!/usr/bin/env bash
set -euo pipefail
if [ "$#" -ne 2 ]; then
echo "用法: $0 template_name functional_list"
exit 1
fi
template="$1"
funclist="$2"
if [ ! -f "$template" ]; then
echo "错误: 模板文件 '$template' 不存在" >&2
exit 1
fi
if [ ! -f "$funclist" ]; then
echo "错误: 功能列表文件 '$funclist' 不存在" >&2
exit 1
fi
mkdir -p jobs
\# 模板基础名(去掉 .inp 后缀)
basename_noext=$(basename "$template" .inp)
\# 逐行读取(包括最后可能没有换行的行)
while IFS= read -r line || [ -n "${line-}" ]; do
\# 删除行首尾空白及可能的回车(处理 CRLF)
line_trimmed="$(printf '%s' "$line" | tr -d '\r' | sed 's/^[[:space:]]*//;s/[[:space:]]*$//')"
\# 跳过空行
if [ -z "$line_trimmed" ]; then
continue
fi
# 取第一部分(空白前的那一段)
first_part="$(printf '%s' "$line_trimmed" | awk '{print $1}')"
# 将文件名部分转为小写并把不安全字符替换为下划线
# 允许的字符: a-z, 0-9, dot, underscore, hyphen
sanitized="$(printf '%s' "$first_part" | tr '[:upper:]' '[:lower:]' | sed 's/[^a-z0-9._-]/_/g')"
outfile="jobs/${basename_noext}_${sanitized}.inp"
# 使用 awk 进行替换,避免 sed 替换中的转义问题
awk -v r="$line_trimmed" '{ gsub(/\{name\}/, r); print }' "$template" > "$outfile"
echo "生成 $outfile"
done < "$funclist"
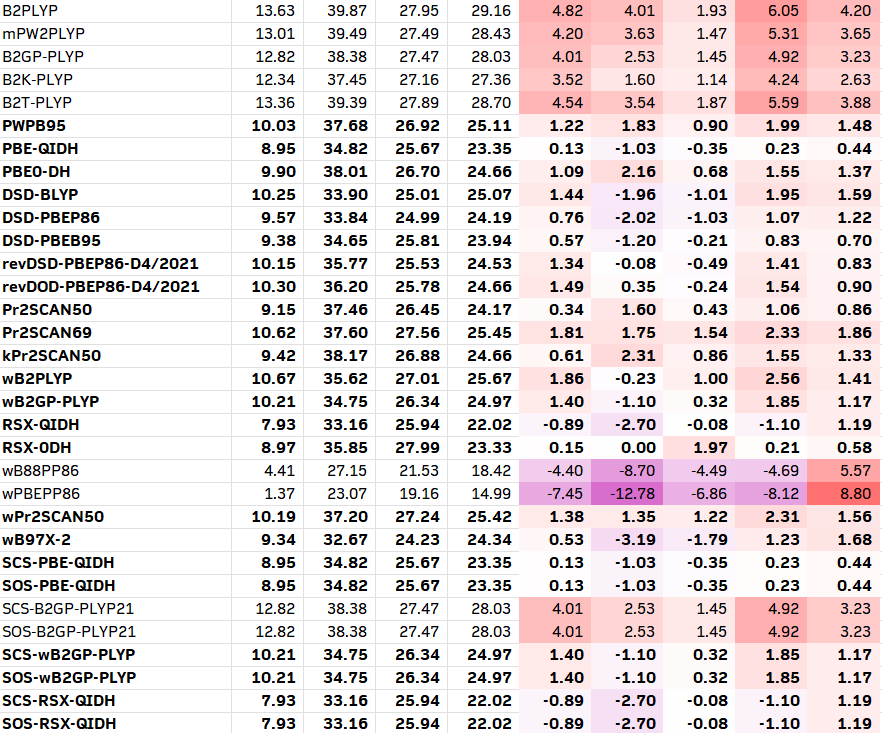
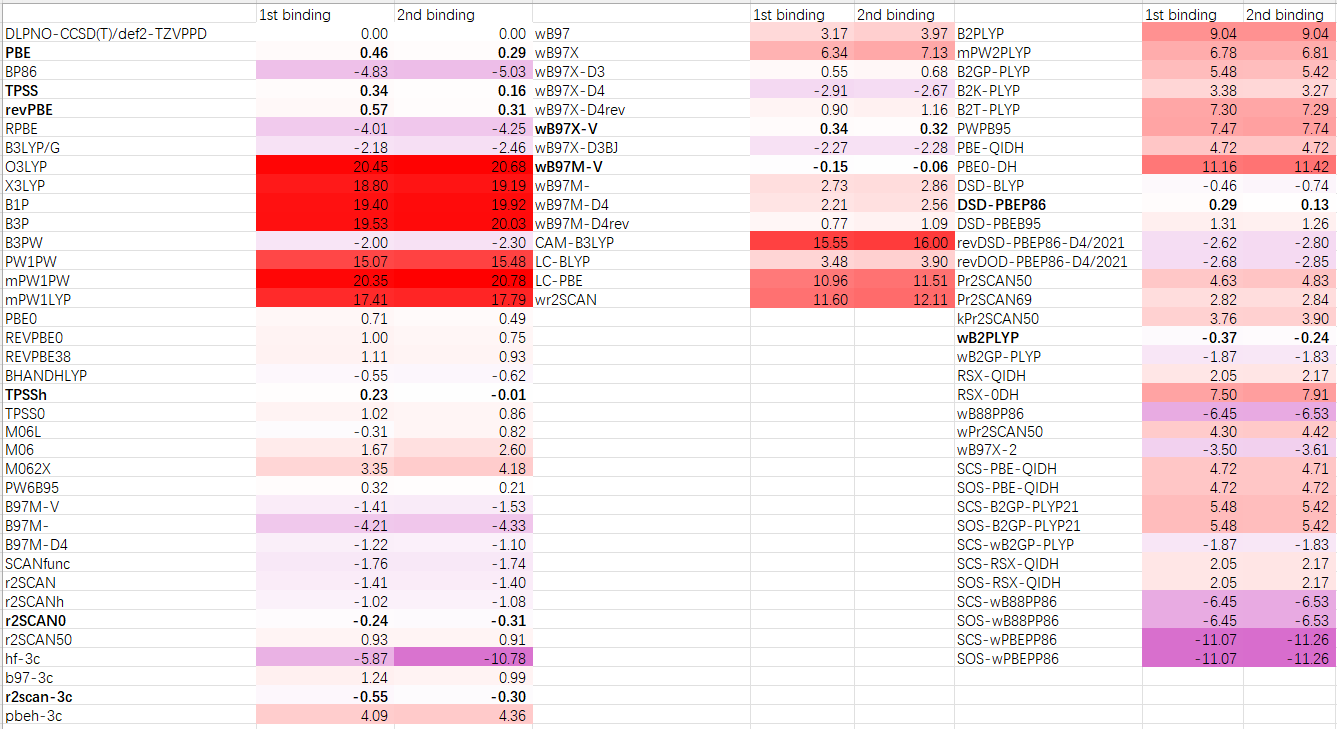
在ORCA 6中,直接内置了将近100种泛函的关键字;除此之外,也可以使用LibXC调用没有内置的泛函。以下是我从ORCA 6手册上复制过来的84个杂化和双杂化列表。有需要的人也可以把纯泛函加进去。
B3LYP/G D3BJ
O3LYP
X3LYP
B1P
B3P
B3PW D3BJ
PW1PW
mPW1PW
mPW1LYP
PBE0 D3BJ
REVPBE0 D3BJ
REVPBE38 D3BJ
BHANDHLYP D3BJ
TPSSh D3BJ
TPSS0 D3BJ
M06L
M06
M062X
PW6B95 D3BJ
B97M-V
B97M-D3BJ
B97M-D4
SCANfunc D3BJ
r2SCAN D3BJ
r2SCANh D3BJ
r2SCAN0 D3BJ
r2SCAN50 D3BJ
wB97
wB97X
wB97X-D3
wB97X-D4
wB97X-D4rev
wB97X-V
wB97X-D3BJ
wB97M-V
wB97M-D3BJ
wB97M-D4
wB97M-D4rev
CAM-B3LYP
LC-BLYP
LC-PBE
wr2SCAN
B2PLYP
mPW2PLYP
B2GP-PLYP
B2K-PLYP
B2T-PLYP
PWPB95
PBE-QIDH
PBE0-DH
DSD-BLYP
DSD-PBEP86
DSD-PBEB95
revDSD-PBEP86-D4/2021
revDOD-PBEP86-D4/2021
Pr2SCAN50
Pr2SCAN69
kPr2SCAN50
wB2PLYP
wB2GP-PLYP
RSX-QIDH
RSX-0DH
wB88PP86
wPBEPP86
wB97M(2)
wPr2SCAN50
wB97X-2
SCS-PBE-QIDH
SOS-PBE-QIDH
SCS-B2GP-PLYP21
SOS-B2GP-PLYP21
SCS-wB2GP-PLYP
SOS-wB2GP-PLYP
SCS-RSX-QIDH
SOS-RSX-QIDH
SCS-wB88PP86
SOS-wB88PP86
SCS-wPBEPP86
SOS-wPBEPP86
准备好相关文件后,让脚本自动在jobs下生成大量输入文件,然后使用合适的for循环批量提交即可。
等到全部运行完成后,使用如下脚本进行分析:
#!/bin/bash
set -euo pipefail
# 至少需要两个参数:至少一个化合物名 + functional_list
if [ "$#" -lt 2 ]; then
echo "用法: $0 compound1 [compound2 ...] functional_list"
exit 1
fi
# functional_list 是最后一个参数
funclist="${@: -1}" # 最后一个参数
# 化合物列表是除最后一个参数以外的所有参数
compounds=("${@:1:$#-1}")
if [ ! -f "$funclist" ]; then
echo "错误: 功能列表文件 '$funclist' 不存在"
exit 1
fi
# 遍历 functional_list 中的每一行
while IFS= read -r line || [ -n "$line" ]; do
# 去掉首尾空白
line_trimmed="$(printf '%s' "$line" | tr -d '\r' | sed 's/^[[:space:]]*//;s/[[:space:]]*$//')"
[ -z "$line_trimmed" ] && continue
# 取第一部分(生成输入时的文件名部分)
first_part="$(printf '%s' "$line_trimmed" | awk '{print $1}')"
sanitized="$(printf '%s' "$first_part" | tr '[:upper:]' '[:lower:]' | sed 's/[^a-z0-9._-]/_/g')"
# 打印原 functional_list 行
printf "%s" "$line_trimmed"
# 遍历所有传入的化合物名
for prefix in "${compounds[@]}"; do
outfile="jobs/${prefix}_${sanitized}.out"
if [ -f "$outfile" ]; then
# 提取能量
energy=$(awk '/FINAL SINGLE POINT ENERGY/ {print $NF}' "$outfile" | tail -n 1)
if [ -n "$energy" ]; then
printf " %s" "$energy"
else
printf " NA"
fi
else
printf " NA"
fi
done
echo
done < "$funclist"
使用方法为:
./analyze_orca_results.sh aaa bbb functional_list
接受一个参数列表,形如aaa bbb ccc等,数量不限,对应每个化合物的名称。针对functional_list里的每一行xxx,检查jobs下对应的.out输出文件aaa_xxx.out, bbb_xxx,out等,找到能量数值,并以xxx(泛函) 化合物aaa的能量 化合物bbb的能量...的格式按照行输出。